dms-view
Interactive visualization tool for deep mutational scanning experiments.
Try out dms-view!//dms-view.github.io
Getting startedTutorial
Upload your own data
Case studies
Deep Mutational Scanning primer
Deploy or develop dms-view
How to upload your own data
dms_view takes three input files.
Below are instructions on how to construct the input files, how to host the input files, and how to load the input files to the site.
Input files
Data file
The data file is the main source of data for dms_view.
This file contains the measurements for the site plot, the measurements for the mutation plot, and the map between the site plot numbering and the protein structure numbering.
The data file is a csv (comma-separated file) and it must have the following columns:
- site: The site plot will be ordered by this column. The values must be ordinal.
- label_site: The site plot will be labeled by this column. The values can be numeric or a string.
- wildtype: The wildtype at a given site. The tooltips will display this information. The values can be numeric or a string.
- mutation: The mutation plot will display this mutation. The values must be a single uppercase letter.
- condition: The experimental condition used in the experiment to generate the data for the site plot and the mutation plot. The dropdown menu will display the conditions and the user can toggle between different conditions.
- protein_chain: The protein chain(s) in the pdb file for a given site. The values must be in a space-separated list. For example, populating the cell with
A Cwill highlight the site on chains A and C (but not B). - protein_site: The protein site in the pdb file for a given site.
The data file must contain at least one column from each of the following categories.
- site_*: The value for a given site for a given metric (represented by
*). The values must be numeric. For example,site_mean. - mut_*: The value for a given site for a given mutation for a given metric (represented by
*). The values must be numeric. For example,mut_mean.
The metric names represented by * above will populate the site metric and mutation metric dropdown menus.
customizing colors in the mutation plot
The default color scheme for the mutation plot indicates the biochemical property of the amino acid. If you would like to use custom colors in the mutation plot, you should include a color_for_mutation column. The cells in the color_for_mutation column should contain either 1) a valid hex color code or 2) the keyword “functional” to indicate the default color scheme. This allows you mix-and-match which site/mutation/site metric combinations use a custom color and which use the default color scheme. Invalid hex color codes or empty cells will default to black.
example: HIV antibody escape
Imagine an experiment to test the effect of alanine mutations on the ability of antibodies to bind to HIV. In this small experiment, the effect of an alanine mutation was measured at position 1 or position 2 for antibody A and antibody B.
Here is what the data file might look like for this experiment.
| site | site_label | wildtype | mutation | condition | protein_chain | protein_site | mut_max | mut_mean | site_median |
|---|---|---|---|---|---|---|---|---|---|
| 1 | pos1 | G | A | Ab1 | A | 27 | 5 | 3.5 | 7 |
| 1 | pos1 | G | A | Ab2 | A | 27 | 0 | 0 | 7 |
| 2 | pos2 | D | A | Ab1 | A | 27 | 0 | 0 | 45 |
| 2 | pos2 | D | A | Ab2 | A | 27 | 100 | 50 | 45 |
Note how the the site_* values are repeated for each mutation at that site.
For a real world example, see the default data file used by dms_view.
protein structure
The protein structure file is a protein data bank (pdb) file. Specifying a pdb file, rather than a pdb ID, allows you to customize the protein structure. This could include removing chains, changing the numbering scheme, and other custom modifications.
The data file columns site, protein_chain, and protein_site map differences in numbering between the site/mutation plot and the protein structure. Specifically, the protein_site column contains the correspondence between the site/mutation values and the protein structure.
If the protein structure has multiple homologous chains, you can specify which chains the site will be plotted on using the a space-separated list in the protein_chain column. See the data file description section for more details.
You can also see the protein file used in the default dms_view view.
description file
The description file is a markdown file. You can use the description file to explain your experiment, acknowledge contributors, or make analysis notes.
You can also see the description file used in the default dms_view view.
Hosting input files
Before you can load any of the three files to dms_view, you must host the files somewhere else with a link to the raw data.
This can be as easy as uploading them to GitHub and linking to the Raw files.
GitHub shows an HTML version by default so you will need to click on the View raw link
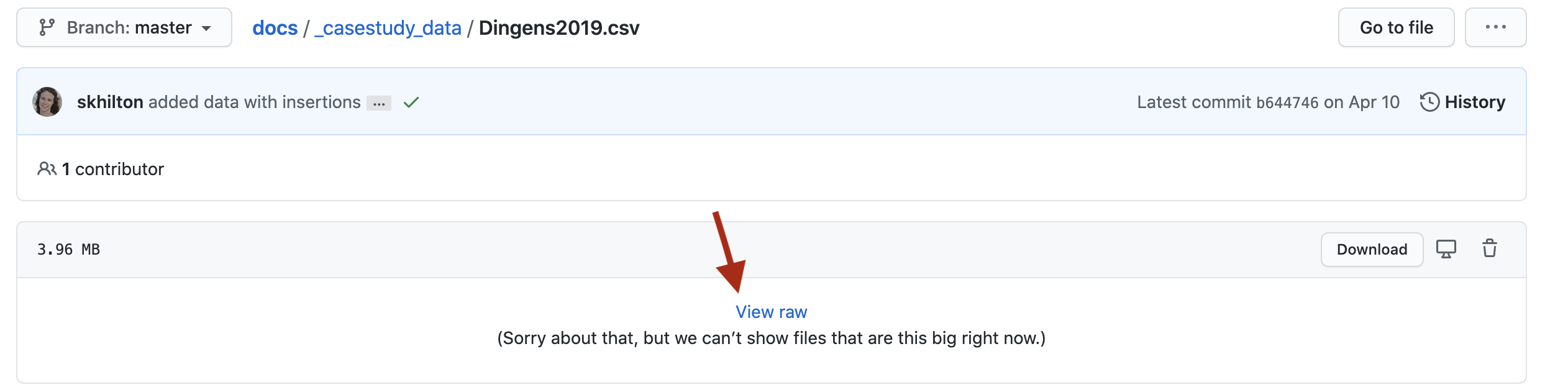 and the URL should start with
and the URL should start with https://raw.githubusercontent.com/.

You can still use dms_view even if you data is a private repository or directory.
The only caveat is that the dms_view URL sharing will not work.
How to load your data
Once you have your input files hosted, you can load the data into dms_view by filling in the form fields on the front page.
The data file form field is above the site plot, the protein file form field is above the protein structure and the description file form field is above the description section at the bottom of the site.
The data file link must be to the raw data on GitHub not the HTML rendering.
See Hosting input files for more information.
All of the data files are saved in the URL. Once the data is loaded, you can share this new URL with others and your data will load for them.